Python教程:pdfplumber提取pdf中的表格数据
2020-10-28 17:15:1011199浏览 · 0收藏 · 0评论
之前讲过的pdfplumber模块,可以用来提取pdf中的表格数据。今天小编就为大家带来实例讲解。
作为一个强大的pdf文件解析工具,pdfplumber库可迅速将pdf文档转换为易于处理的txt文档,并输出pdf文档的字符、页面、页码等信息,还可进行页面可视化操作。使用pdfplumber库前需先安装,即在cmd命令行中输入:
pip install pdfplumber
pdfplumber库提供了两种pdf表格提取函数,分别为.extract_tables( )及.extract_table( ),两种函数提取结果存在差异。为进行演示,我们网站上下载了一份短期融资券主体信用评级报告,为pdf格式。任意选取某一表格,其界面如下:
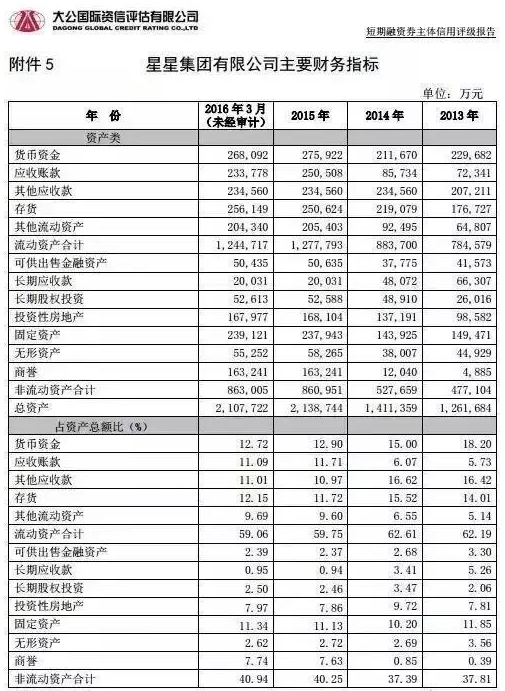
(1).extract_tables( )
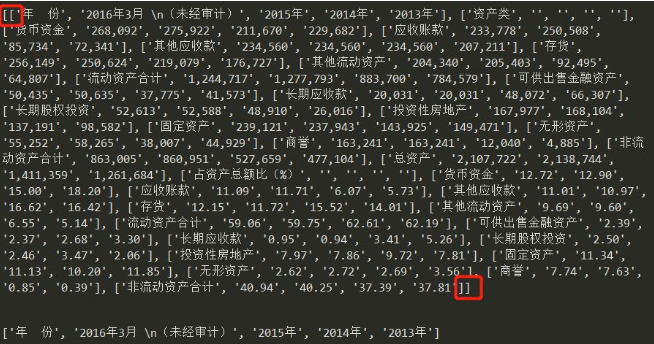
可输出页面中所有表格,并返回一个嵌套列表,其结构层次为table→row→cell。此时,页面上的整个表格被放入一个大列表中,原表格中的各行组成该大列表中的各个子列表。若需输出单个外层列表元素,得到的便是由原表格同一行元素构成的列表。例如,我们执行如下程序:
import pdfplumber
with pdfplumber.open(r'F:python财务报表主体评级报告.pdf') as pdf:
page = pdf.pages[45] #设置操作页面
for row inpage.extract_tables() :
print(row)
print(row[0]) #打印外层列表第一个元素
输出结果:
(2).extract_table( )
返回多个独立列表,其结构层次为row→cell。若页面中存在多个行数相同的表格,则默认输出顶部表格;否则,仅输出行数最多的一个表格。此时,表格的每一行都作为一个单独的列表,列表中每个元素即为原表格的各个单元格内容。若需输出某个元素,得到的便是具体的数值或字符串。如下:
with pdfplumber.open(r'F:python财务报表主体评级报告.pdf') as pdf:
page = pdf.pages[45]
for row in page.extract_table() :
print(row)
print(row[0]) #打印每个列表对应的第一个元素
输出结果:

今天的分享到这里就结束啦,对pdfminer知识遗忘的小伙伴回顾以往文章:进阶PDF,就用Python(pdfminer.six和pdfplumber模块)

关注公众号,随时随地在线学习
python学习网
认证0级讲师

 分享到微博
分享到微博 微信扫一扫
微信扫一扫
 流芳
流芳



